每日經濟新聞 2025-02-02 23:13:01
DeepSeek大模型的低成本高效能,不僅挑戰了硅谷巨頭,也讓華爾街感到焦慮。復旦大學計算機學院副教授鄭驍慶認為,DeepSeek在工程優化方面取得了顯著成果,實現了性能與成本的平衡。但他指出,DeepSeek并不會對芯片采購量或出貨量產生太大的影響,相反,隨著更多企業加入到大模型的應用行列,對芯片的需求可能會增加。
每經記者 宋欣悅 每經編輯 高涵

近日,中國AI初創公司深度求索(DeepSeek)在全球掀起波瀾,硅谷巨頭恐慌,華爾街焦慮。
短短一個月內,DeepSeek-V3和DeepSeek-R1兩款大模型相繼推出,其成本與動輒數億甚至上百億美元的國外大模型項目相比堪稱低廉,而性能與國外頂尖模型相當。
作為“AI界的拼多多”,DeepSeek還動搖了英偉達的“算力信仰”,旗下模型DeepSeek-V3僅使用2048塊英偉達H800 GPU,在短短兩個月內訓練完成。除了性價比超高,DeepSeek得到如此高的關注度,還有另一個原因——開源。DeepSeek徹底打破了以往大型語言模型被少數公司壟斷的局面。
被譽為“深度學習三巨頭”之一的楊立昆(Yann LeCun)在社交平臺X上表示,這不是中國追趕美國的問題,而是開源追趕閉源的問題。OpenAI首席執行官薩姆·奧爾特曼(Sam Altman)則罕見地表態稱,OpenAI在開源AI軟件方面“一直站在歷史的錯誤一邊”。
DeepSeek具有哪些創新之處?DeepSeek的開源策略對行業有何影響?算力與硬件的主導地位是否會逐漸被削弱?
針對上述疑問,《每日經濟新聞》記者(以下簡稱NBD)專訪了復旦大學計算機學院副教授、博士生導師鄭驍慶。他認為,DeepSeek在工程優化方面取得了顯著成果,特別是在降低訓練和推理成本方面。“在業界存在著兩個法則,一個是規模法則(Scaling Law),另外一個法則是指,隨著技術的不斷發展,在既有技術基礎上持續改進,能夠大幅降低成本。”
對于DeepSeek選擇的開源策略,鄭驍慶指出,“開源模型能夠吸引全世界頂尖人才進行優化,對模型的更新和迭代有加速作用。”此外,開源模型的透明性有助于消除使用安全的顧慮,促進全球范圍內人工智能技術的公平應用。
盡管DeepSeek的模型降低了算力需求,但鄭驍慶強調,AI模型仍需要一定的硬件基礎來支持大規模訓練和推理。此外,大規模數據中心和預訓練仍是AI發展的重要組成部分,但未來可能會更注重高質量數據的微調和強化學習。

鄭驍慶 圖片來源:受訪者供圖
NBD:微軟CEO薩提亞·納德拉在微軟2024年第四季度財報電話會上提到,DeepSeek“有一些真正的創新”。在您看來,DeepSeek有哪些創新點呢?
鄭驍慶:在深入研讀DeepSeek的技術報告后,我們發現,DeepSeek在降低模型訓練和推理成本方面采用的方法,大多基于業界已有的技術探索。比如,鍵值緩存(Key-Value cache)管理,對緩存數據進行壓縮。另一個是混合專家模型(MoE,Mixture of Experts),實際上是指,在推理的時候,只需使用模型的某一個特定的模塊,而不需要所有模型的網絡結構和參數都參與這個推理過程。
此外,Deepseek還采用了FP8混合精度訓練的技術手段。這些其實之前都有所探索,而DeepSeek的創新之處就在于,很好地將這些能夠降低技術和推理成本的技術整合起來。
NBD:您認為DeepSeek現階段的技術水平上是否已經接近或者達到了全球領先水平呢?
鄭驍慶:DeepSeek目前在現有技術基礎上,包括網絡結構訓練算法方面,實現了一種階段性的改進,并非是一種本質上的顛覆性創新,這一點是比較明確的。其改進主要是針對特定任務,例如,DeepSeek在數學、代碼處理以及推理任務等方面,提出了一種在性能與成本上相對平衡的解決方案。然而,它在開放領域(open domain)上的表現,優勢并不是十分明顯。
在業界存在著兩個法則,一個是規模法則(Scaling Law),即模型的參數規模越大、訓練數據越多,模型就會更好。另外一個法則是指,隨著技術的不斷發展,在既有技術基礎上持續改進,能夠大幅降低成本。
比如說,以GPT-3為例,早期它的成本就很高。但隨著研究的深入,研究人員逐漸清楚哪些東西是工作的,哪些東西是不工作的。研究人員基于過往的成功經驗,研究目標會逐漸清晰,成本實際上也會隨之降低。
DeepSeek的成功,我更覺得可能是工程優化上的成功。當然也非常高興看到中國的科技企業在大模型的時代,在性能與成本的平衡方面取得了顯著進展,不斷推動大模型的使用和訓練成本下降。符合剛才我提到的第二個法則的情況之下,走到世界前列。
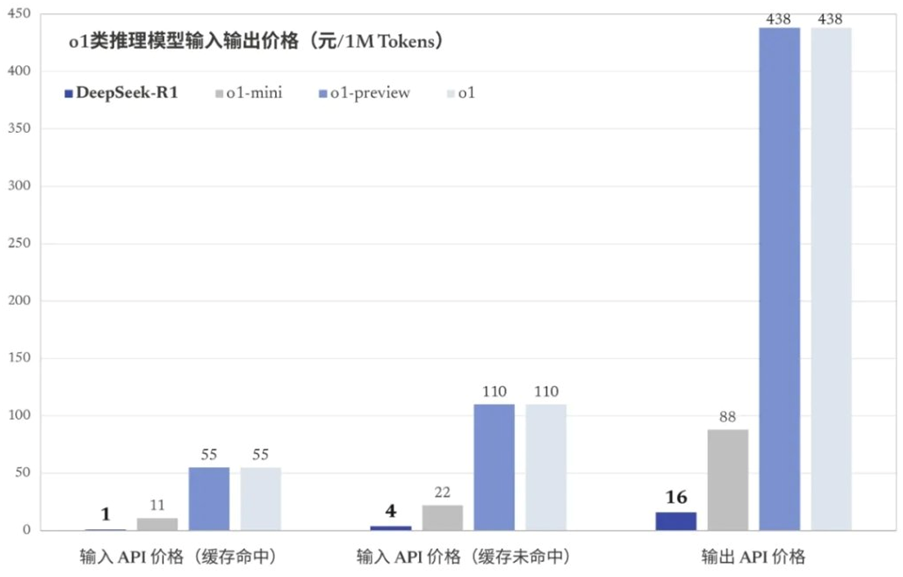
NBD:DeepSeek旗下模型的最大亮點之一是在訓練和推理過程中顯著降低了算力需求。您認為這種低成本大效能的技術創新,長期來看,會對英偉達等芯片公司產生什么影響呢?
鄭驍慶:我個人認為,它并不會對芯片采購量或出貨量產生太大的影響。
首先,像DeepSeek或者類似的公司,在尋找有效的整合解決方案時,需要進行大量的前期研究與消融實驗。所謂的消融實驗,即指通過一系列測試來確定哪個方案是有效的以及哪些方案的整合是有效的。而這些測試就非常依賴于芯片,因為芯片越多,迭代次數就越多,就越容易知道哪個東西工作或者哪個東西不工作。
比如說,DeepSeek的訓練預算不到600萬美元。它的技術報告中提到,不到600萬美元的資金,是按照GPU的小時數(每小時兩美元)來估算的。也就是說,他們基于之前的很多研究,把整條訓練流程都已經搞清楚的情況之下(哪些是工作,哪些不工作的),重新走一遍。它的GPU的運算速度是多少,運算小時數是多少,然后再乘以每小時兩美元得到的這個結果。報告中也提到了,600萬美元其實沒有包含先期研究成本,比如,在結構上的探索、在算法上的探索、在數據上采集上的探索成本,也沒有涵蓋消融實驗的開銷以及設備的折舊費。所以,我個人判斷,對英偉達其實影響不是那么大。
另外,DeepSeek的研究表明,很多中小企業都能用得起這樣的大模型。盡管訓練成本的下降可能會暫時減少對GPU的需求,但大模型變得更加經濟,會使原本因為模型成本太高而不打算使用大模型的企業,加入到使用模型的行列,反而會增加對于芯片的需求。
NBD:隨著DeepSeek-V3、R1等低成本大模型的問世,傳統的大規模數據中心和高投入的大模型訓練是否仍然值得繼續推進呢?
鄭驍慶:我覺得仍然值得。因為首先DeepSeek模型是語言模型,還沒有擴展到多模態,甚至于我們以后要研究世界模型。那么一旦引入多模態之后,對算力的要求和基礎設施要求就會成指數的增長。因為人工智能不可能僅僅局限于語言體本身,語言只是智慧的一種表現,而在這方面的探索仍然需要這樣的一個基礎設施。
剛才也提到DeepSeek其實是在很多先期研究的基礎之上,找到了一條性能和成本平衡的一個解決方案。先期研究包括各種各樣的嘗試,怎樣去加速它呢?這個還是需要強大的硬件支持。否則,每迭代一次,就可能需要長達一年多的時間,這顯然是無法趕上現在AI軍備競賽的。而如果有幾萬張卡,迭代可能幾天就完成了。
另外就是應用方面。即便是模型的推理成本再低,當需要支持數千、數萬甚至更大規模的并發使用時,仍然需要一個配備大量顯卡的強大基礎架構來確保穩定運行。
我覺得大規模預訓練這一波潮流可能會弱化,可能不會成為下一步大家爭奪的主戰場。之前這個領域曾是競爭激烈的戰場,但現在看來,成本和產出之間的比例正逐漸趨于緊縮。但是后面兩步——高質量數據的微調和基于強化學習的人類偏好對齊,我相信未來會有更多的投入。

NBD:DeepSeek采用開源模式,與許多國外大模型巨頭閉源的做法不同。您怎么看開源模型在推動AI行業發展中的作用?
鄭驍慶:DeepSeek目前受到了廣泛地關注和認可。從開源模型與閉源模型的角度來看,我們觀察到,開源模型在積累了以往研究成果的基礎上,在目標明確的情況之下,借助于各種訓練技巧以及模型結構上的優化,特別是吸收先前研究者在大模型領域已驗證有效的原理和方法,開源模型已能夠大致追上閉源模型。
開源模型最大的好處就在于,一旦模型開源,全球的頂尖人才都能基于這些代碼進行進一步的迭代與優化,這無疑加速了這個模型的更新與發展進程。相比之下,閉源模型肯定是沒有這樣的能力的,只能靠擁有這個閉源模型所屬機構的內部人才去推動模型的迭代,迭代速度相對受限。
另外,開源模型透明開放,也緩解了公眾對于大模型使用安全的一些顧慮。如果模型閉源,大家在使用過程當中可能或多或少會有一些顧慮。而且開源模型對于人工智能的普及以及全球范圍內的公平應用起到了非常好的促進作用,特別是技術平權方面。也就是說,當一項科學技術發展起來以后,全世界的人,不管來自哪個國家、身處何地,都應用享有平等地享受這種技術所帶來的優勢及其產生的經濟效益。
NBD:DeepSeek團隊成員多為國內頂尖高校的應屆畢業生、在校博士生。您認為中國AI是否存在獨特的競爭優勢?
鄭驍慶:我覺得我們的AI上面的競爭優勢,其實是我們的人才數量上的優勢。這幾年,從我個人來看,我們的高等教育,包括碩士、博士的培養,有了長足進步。現在從中國的頭部高校來看,對博士生、碩士生的培養已經比較接近于美國。
在這樣的情況之下,我們的基礎高等教育質量的提升,使得我們儲備了大量的人才。在這樣的過程當中,我們能夠對現有的技術進行迅速的消化。
實際上,美國許多大模型研究團隊,不乏有華人的身影。大家開玩笑說,現在的人工智能競爭是在中國的中國人和在美國的中國人競爭。要說劣勢,其實我覺得還是很遺憾的,那就是我們很少能有顛覆性的創新。
如需轉載請與《每日經濟新聞》報社聯系。
未經《每日經濟新聞》報社授權,嚴禁轉載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯系索取稿酬。如您不希望作品出現在本站,可聯系我們要求撤下您的作品。
歡迎關注每日經濟新聞APP














