每日經(jīng)濟(jì)新聞 2025-01-27 09:01:04
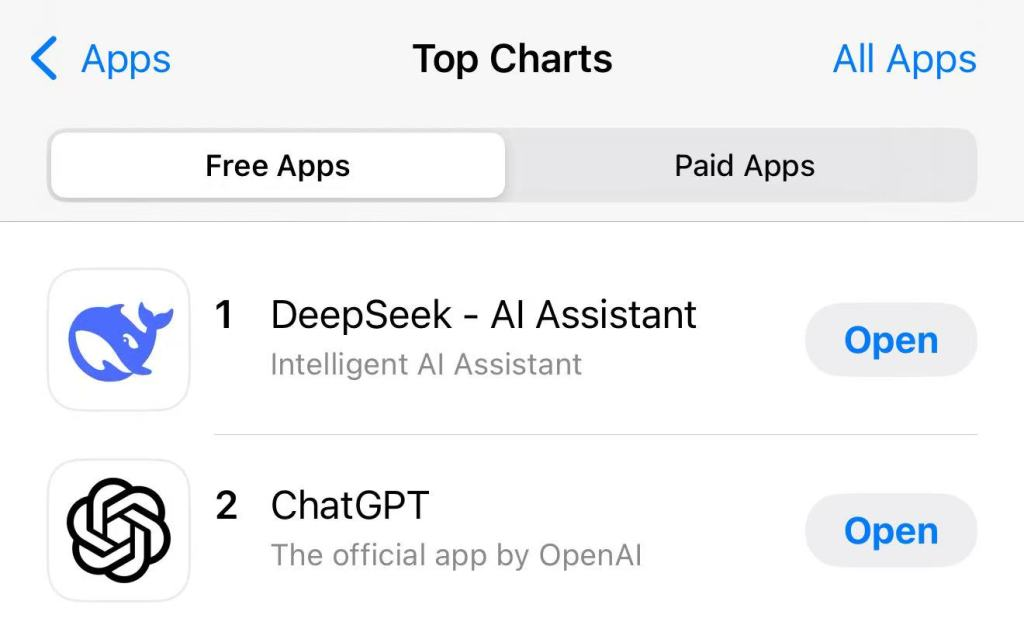
1月27日,DeepSeek應(yīng)用登頂美區(qū)和中國區(qū)應(yīng)用商店免費(fèi)榜。其爆火原因主要為性能和成本,成本低且性能卓越,吸引大量用戶。該模型代碼和訓(xùn)練方法完全開源,成為開源社區(qū)下載量最高的大模型。DeepSeek成立于2023年5月,背后是幻方量化,創(chuàng)始人梁文鋒是一位80后技術(shù)理想主義者。
每經(jīng)編輯 畢陸名
1月27日,DeepSeek應(yīng)用登頂蘋果美國地區(qū)應(yīng)用商店免費(fèi)APP下載排行榜,在美區(qū)下載榜上超越了ChatGPT。同日,蘋果中國區(qū)應(yīng)用商店免費(fèi)榜顯示,DeepSeek成為中國區(qū)第一。
據(jù)廣州日報報道,“DeepSeek爆火的原因主要可以歸結(jié)為兩點(diǎn):性能和成本。”薩摩耶云科技集團(tuán)首席經(jīng)濟(jì)學(xué)家鄭磊告訴記者。DeepSeek解釋稱,R1在后訓(xùn)練階段大規(guī)模使用了強(qiáng)化學(xué)習(xí)技術(shù),在僅有極少標(biāo)注數(shù)據(jù)的情況下,極大提升了模型推理能力。這種卓越的性能不僅吸引了科技界的廣泛關(guān)注,也讓投資界看到了其巨大的商業(yè)潛力。
更為關(guān)注的是,DeepSeek R1真正與眾不同之處在于它的成本——或者說成本很低。DeepSeek的R1的預(yù)訓(xùn)練費(fèi)用只有557.6萬美元,僅是OpenAI GPT-4o模型訓(xùn)練成本的不到十分之一。同時,DeepSeek公布了API的定價,每百萬輸入tokens 1元(緩存命中)/4元(緩存未命中),每百萬輸出tokens 16元。這個收費(fèi)大約是OpenAI o1運(yùn)行成本的三十分之一,也因此,DeepSeek被稱為AI界的“拼多多”。
“DeepSeek以較低的成本實現(xiàn)了高性能的AI模型,這使得其在市場競爭中具備了顯著的優(yōu)勢,這種成本效益比無疑會吸引大量企業(yè)和個人用戶選擇其產(chǎn)品和服務(wù)。”北京社科院副研究員王鵬表示。
鄭磊直言,DeepSeek對硬件市場產(chǎn)生了重大影響,因為它可能會降低人工智能模型的硬件成本,從而推動人工智能技術(shù)的發(fā)展。
另據(jù)媒體報道,為了訓(xùn)練模型,幻方量化在美國芯片出口限制之前獲得了超過1萬塊英偉達(dá)GPU,盡管有說法稱DeepSeek大約有5萬顆H100芯片,但尚未得到公司官方證實。
早在去年12月,該公司推出的DeepSeek-V3通過優(yōu)化模型架構(gòu)和基礎(chǔ)設(shè)施等方式,展現(xiàn)了極致性價比。從該團(tuán)隊正式發(fā)布的技術(shù)報告來看,包括預(yù)訓(xùn)練、上下文長度外推和后訓(xùn)練在內(nèi),DeepSeek-V3完整訓(xùn)練只需2.788M H800 GPU小時,其訓(xùn)練成本僅為557萬美元,但該模型實現(xiàn)了與GPT-4o和Claude Sonnet 3.5(來自美國人工智能企業(yè)Anthropic)等頂尖模型相媲美的性能。
當(dāng)時著名人工智能科學(xué)家卡帕西(Andrej Karpathy)就發(fā)文表示,這種級別的能力通常需要接近16000顆GPU的集群,而目前市場上的集群規(guī)模更是達(dá)到了10萬顆GPU左右。

盡管尚不清楚最新發(fā)布的DeepSeek-R1的訓(xùn)練成本,但其在服務(wù)價格上,相較性能相當(dāng)?shù)腛penAI的o1也有明顯優(yōu)勢。DeepSeek-R1的API服務(wù)定價為每百萬輸入tokens 1元(緩存命中)/4元(緩存未命中),分別是OpenAI o1的2%和3.6%。
除了極致性價比,讓DeepSeek的大模型脫穎而出的是其代碼和訓(xùn)練方法的完全開源。
目前,DeepSeek-R1已經(jīng)一躍成為開源社區(qū)Hugging Face上下載量最高的大模型,下載量達(dá)10.9萬次,這意味著全球的開發(fā)人員正在試圖了解這一模型以輔助他們自己的AI開發(fā)。DeepSeek的服務(wù)器也于26日出現(xiàn)了局部服務(wù)波動。這一問題在數(shù)分鐘內(nèi)得到解決,或與新模型發(fā)布后的訪問量激增有關(guān)。
DeepSeek創(chuàng)始人梁文鋒在接受媒體采訪時也表示:“在顛覆性的技術(shù)面前,閉源形成的護(hù)城河是短暫的。即使OpenAI閉源,也無法阻止被別人趕超。”
梁文鋒認(rèn)為:“開源更像一個文化行為,而非商業(yè)行為。給予其實是一種額外的榮譽(yù)。一個公司這么做也會有文化的吸引力。”Meta首席人工智能科學(xué)家楊立昆(Yann LeCun)也在社交媒體表示,DeepSeek成功的最大收獲不是來自中國競爭對手的加劇威脅,而是保持人工智能模型開源的價值,以便任何人都能受益。
“他們有了新的想法,并在其他人的工作基礎(chǔ)上加以實現(xiàn)。由于他們的工作成果已發(fā)表并開源,因此每個人都可以從中受益。”楊立昆表示,“這就是開放研究和開源的力量。”
DeepSeek成立于2023年5月,其背后是國內(nèi)對沖基金巨頭幻方量化。
2023年11月2日,DeeSeek推出首個模型DeepSeek Coder,該模型免費(fèi)供商業(yè)使用且完全開源。2023年11月29日,DeepSeek LLM上線,其參數(shù)規(guī)模達(dá)到67B,性能接近GPT-4,同時還發(fā)布了該模型的聊天版本DeepSeek Chat。
真正讓Deepseek在AI界出圈的,是其在2024年5月開源的第二代MoE大模型DeepSeek-V2。該模型在性能上比肩GPT-4 Turbo,價格卻只有GPT-4的百分之一,DeepSeek由此被稱作“價格屠夫”、“AI界的拼多多”。
隨后的2024年下半年,這家公司還先后發(fā)布了DeepSeek R1-lite-preview和DeepSeek-V3。
到了2025年推出的R1模型,在數(shù)學(xué)能力測試中,該模型在MATH基準(zhǔn)測試上達(dá)到了77.5%的準(zhǔn)確率,與OpenAI的o1不相上下;在編程領(lǐng)域,R1在Codeforces評測中達(dá)到了2441分的水平,高于96.3%的人類參與者。
而這一切,是在不到600萬美元的投入和2048塊低性能的H800芯片的條件下完成的,訓(xùn)練時間僅用兩個月。這種“四兩撥千斤”的模式,顛覆了人們對OpenAI“大力出奇跡”式的固有認(rèn)知,結(jié)果令全球側(cè)目。
幻方量化和DeepSeek創(chuàng)始人梁文鋒,畢業(yè)于浙江大學(xué)信息與通信工程專業(yè)。業(yè)內(nèi)口碑稱,這是一位極致的80后技術(shù)理想主義者。創(chuàng)立幻方,梁文鋒就在幕后潛心鉆研技術(shù),在DeepSeek時代,其依舊延續(xù)著低調(diào)作風(fēng),和一線研究員一樣,每天“看論文,寫代碼,參與小組討論”。
據(jù)證券時報報道,一名人工智能行業(yè)資深業(yè)內(nèi)人士向記者分析稱,DeepSeek以200人左右的小團(tuán)隊,且不依靠外部融資,做出了一個有性價比并被全球主流AI界人士所認(rèn)可的大模型。“一是他們在早期就買了很多算力卡,投入了很多資源做研究;二是他們是做量化的,不像大廠有其他各種各樣的盈利需求,也跟他們不構(gòu)成競爭關(guān)系,能更專注于模型開發(fā)。”該業(yè)內(nèi)人士表示。
每日經(jīng)濟(jì)新聞綜合廣州日報、第一財經(jīng)、證券時報
封面圖片來源:每日經(jīng)濟(jì)新聞
如需轉(zhuǎn)載請與《每日經(jīng)濟(jì)新聞》報社聯(lián)系。
未經(jīng)《每日經(jīng)濟(jì)新聞》報社授權(quán),嚴(yán)禁轉(zhuǎn)載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯(lián)系索取稿酬。如您不希望作品出現(xiàn)在本站,可聯(lián)系我們要求撤下您的作品。
歡迎關(guān)注每日經(jīng)濟(jì)新聞APP

Copyright ? 2025 每日經(jīng)濟(jì)新聞報社版權(quán)所有,未經(jīng)許可不得轉(zhuǎn)載使用,違者必究。
廣告熱線? 北京: 010-57613265,?上海: 021-61283008,?廣州: 020-84201861,?深圳: 0755-83520159,?成都: 028-86512112













